Sharing My AWS (AMAZON WEB SERVICES) Notes
Welcome to my notes on AWS. I hope that sharing them, will help you quickly get an introduction or act as a refresher while you navigate the labyrinth of AWS. I started with watching a few youtube videos and, for me, youtube videos are too time-consuming and can be frustrating to watch twice, especially when you are short on time and just want to get the information you need. So these notes I took a year ago to save myself from endless videos when I started looking into AWS and considered AWS certifications.
Here you will not find a well-written blog on how to AWS, instead raw badly written notes on various services. I invite you to add your notes on more services or suggestions. Here we go:
SERVICES PROVIDED BY AMAZON:
NETWORKING & CONTENT DELIVERY:
Lambda, EC2, VPC, Route53
STORAGE:
S3 (Simple storage service), Glacier, EFS (Elastic File service), Storage Gateway
DATABASES:
RDS (Relational Database Service), DynamoDB, Redshift, Elasticache
MIGRATION:
Snowball, DMS (Database migration services), SMS (Server Migration Service)
ANALYTICS:
Athena, EMR (Elastic Map Reduce), Cloud Search, Elastic Search, Kinesis, Data Pipeline
SECURITY & IDENTITY:
IAM (Identity Access Management), Inspector, Certificate Manager, Directory Service, WAF (Web Application Firewall), Artifacts
MANAGEMENT TOOLS:
Cloud Watch, Cloud Formation, Cloud Trail, Opsworks, Config, Service Catalog, Trusted Advisor
IAM (IDENTITY ACCESS MANAGEMENT)
IAM allows you to manage users and their level of access to the AWS Console.
IAM gives you:
Centralized control of AWS account.
Shared access to your AWS account.
Granular Permission means enabling different levels of access to different users within the organization.
Identity Federation (including Active Directory, FB, LinkedIn etc)
Multifactor Authentication- provides additional security for AWS account settings and resources.
Provide temporary access to users/devices, and services.
IAM consists of the following:
Users
Groups: Collection of users under one set of permission.
Roles: Used to define a set of permissions.
Policy Documents: Defines one or more permission, policies attached to a user, group or role.
Key Points
IAM is universal: It doesn’t apply to regions.
The “root account” is simply the account created when you first set up your AWS account. It has complete Admin access.
New Users have no permission when first created.
New Users are assigned Access Key ID & Secret Access Keys when first created.
These keys are not the same as a password, and you cannot use the Access Key ID & Secret Access Key to log in to the AWS Management Console.
You can use this to access AWS via the APIs and Command Line Interface(CLI) from your local desktop.
You only get to view Access Key ID & Secret Access Key once. If you lose them, you have to regenerate them, therefore, save them in a secure location.
Always set up Multifactor Authentication (MFA) on your root account.
You can create and customize your password rotation policies.
SERVERLESS COMPUTING
Serverless allows you to run application code in the cloud without worrying about managing any server. AWS handles the infrastructure management task so that you can focus on writing code. Management tasks handled by AWS are capacity provisioning, patching, Auto Scaling and High availability.
Advantages of Serverless:
Speed to market (without managing infrastructure)
Super scalable.
Lower cost.
Focus on code only.
LAMBDA
Lambda is a serverless computing service, which allows you to run your code without any AWS service. Supported Languages are Node.js, Java, Python, C#, Go, and Ruby.
Lambda Pricing: Pricing is based on the number of requests, their duration and the amount of memory used by the Lambda function
Number of requests: First 1 million requests are free. $0.02 per 1 million requests thereafter.
Duration**:** Charged in 1ms increment. This is calculated from the time your code begins executing until it returns or otherwise terminates, rounded up to the nearest 100ms.
Price per GB-second: The price depends on the amount of memory you allocate to your function. You are charged $ 0.00001667 for every GB-second used.
Lambda is an Event-Driven and serverless application using an Event-Driven Architecture.
The lambda function can be automatically triggered by other AWS services or directly from any web or mobile app. These events could be changes made to data in S3 or DynamoDB table.
AWS services that can invoke Lambda functions are DynamoDB, Kinesis, SQS, Application Load Balancer, API Gateway, CloudFront, S3, SNS, SES, CloudFormation, CloudWatch, CLoudCommit, CloudPipeline etc.
Key Points:
Cost-Effective
Continuous Scaling
Lambda function is independent: Each event will trigger a single function.
Event-Driven
Serverless Technology.
Version Control with Lambda:
Versioning: When versioning is used in AWS Lambda, you can publish one or more versions of your lambda function. As a result, you can work with different variations of your Lambda function in your development workflows, such as development, beta and production.
Each Lambda function version has a unique Amazon Resource Name (ARN). After you publish a version, it is immutable (that is it can’t be changed).
AWS Lambda maintains your function code in the $LATEST version. When you update your function code, AWS Lambda replaces the code in the $LATEST version of the Lambda function.
Qualified/Unqualified ARNs
You can refer to this function using its ARN. There are two ARNs associated with this initial version:
Qualified ARN: The function ARN with the version suffix.
arn:aws:lambda:aws-region:acct-id:function:helloworld:$LATEST
- Unqualified ARN: The function ARN without the version suffix.
arn:aws:lambda:aws-region:acct-id:function:helloworld
Key Points:
Can have multiple versions of lambda functions.
The latest version will use $latest.
The qualified version will use $latest, unqualified will not have it.
Versions are immutable.
Can split traffic using aliases to different versions.
Cannot split traffic with $latest, instead create an alias to latest.
Lambda Concurrent execution Limit:
The default concurrent execution limit is 1,000 per second.
Sometimes on serverless websites, websites hit the limit at some point.
If sites hit the limit then invocations are rejected-429 HTTP status code, which means there are too many requests.
The remedy is to get the limit raised by AWS support.
EC2 (ELASTIC COMPUTE CLOUD)

EC2 is secure, resizable compute capacity in the cloud.
It’s like a virtual machine, only hosted in AWS instead of your own data center.
Designed to make web-scale cloud computing easier for developers.
ADVANTAGES:
Pay only for what you use.
No wasted capacity: Select the capacity you need and you can grow and shrink the capacity as per the requirements.
Pricing Options:
On-Demand: By default pricing option. Payment is done by the hour or the second depending on the type of instance you run. Low-cost pricing option.
Reserved: Reserved capacity for one or three years. These instances operate at a regional level.
Spot: Enables you to bid whatever price you want for instance capacity, providing even greater savings if your applications have flexible start and end times. Purchased unused capacity at a discount of up to 90%.
Dedicated: Most expensive option. Used for security purposes**,** by using a space that is not shared by anyone.
Uses of Instances:
On-Demand: Applications with short-term, spiky, or unpredictable workloads that cannot be interrupted. Applications being developed or tested on Amazon EC2 for the first time
Reserved: Predictable usage or steady state, Specific capacity requirements, Pay upfront.
Spot Instance: Applications that have flexible start and end times, that are only feasible at very low compute prices and suitable for the urgent need for large amounts of additional computing capacity.
Dedicated hosts: Compliance requirements and regulatory requirements that may not support multi-tenant virtualization. Licensing which does not support multi-tenancy or cloud deployments.
EC2 INSTANCE TYPES:
Instance type determines the hardware configuration and capabilities of the host computers when an instance or virtual machine is running. Instance types comprise varying combinations of CPU, memory, storage, and networking capacity and give you the flexibility to choose the appropriate mix of resources for your applications. Each instance type includes one or more instance sizes, allowing you to scale your resources to the requirements of your target workload.
Select an instance type based on the requirement of your application.
For more detail: https://aws.amazon.com/ec2/instance-types/
ROUTE 53

Route 53 is Amazon’s DNS (Domain Name System) service. Allow you to map your domain names to:
EC2 instances
Load Balancers
S3 Buckets
ELASTIC LOAD BALANCERS

Elastic Load Balancing automatically distributes incoming application traffic across multiple servers. Capacity easily increased when needed.
Types of Load Balancers:
Application Load Balancers:
Operates at the OSI layer 7, and makes routing and routing decisions based on the information. Best suited for load balancing of HTTP and HTTPS traffic. They are intelligent, and you can create advanced request routing, sending specified requests to specific web servers.
Network Load balancers:
Best suited for load balancing of TCP traffic where extreme performance is required. Operating at the connection level (Layer 4), basically, layer 4 wants super fast performance & super fast speed. Network Load Balancers are capable of handling millions of requests per second while maintaining ultra-low latencies. It is AWS’s most expensive load balancer but is used in production especially when the latency is an issue.
CLASSIC LOAD BALANCERS:
They are the legacy Elastic Load Balancers. Load balancing of HTTP/HTTPS applications and use Layer 7-specific features, such as X-Forwarded and sticky sessions. You can also use strict Layer 4 load balancing for applications that rely purely on the TCP Protocol. Classic Load Balancer is intended for applications that were built within the EC2-Classic network.
X-Forwarded-For Header: Identify the originating IPv4 address of a client connecting through a load balancer
CLOUD FRONT
Cloud front is Amazon’s CDN (Content delivery network).
CDN is a system of distributed servers (network) that deliver webpages and other web content to a user based on the geographic locations of the user, the origin of the webpage, and a content delivery server. CDN is easy and cost-effective way to distribute content with low latency and high data transfer speed.
Explain by an example, Imagine a website running from London, and has users at geographically dispersed all around the world. So, instead of each user accessing the files directly between the users, we introduce this concept called Edge locations. An edge location is simply a collection of servers that are in geographically dispersed data centers. And these are used by CloudFront to keep a cache of copies of your object, and this means that instead of requesting content from a server in London, users can access that content from the edge location. So, once the request is made, the edge location forwards the request to the server in London, so it downloads the files and it caches them locally. This provides a much faster response time. It means that your requests are only going to that local edge location, they’re not going all the way to the main server.

Edge Location: Location where content is cached and can also be written. Separate to an AWS Region/Availability Zone.
Origin: This is the origin of all the files that the CDN will distribute. Origins can be an S3 Bucket, an EC2 Instance, an Elastic Load Balancer, or Route53.
Distribution: This is the name given the origin and configuration settings for the content to distribute using CDN.
Web Distribution: Typically used for websites. HTTP/HTTPS
RTMP (Real-Time Messaging Protocol): Used for Media Streaming.
Amazon CloudFront can be used to deliver your entire website, including dynamic, static, streaming and interactive content using a global network of edge locations. Requests for your content are automatically routed to the nearest edge location, so content is delivered with the best possible performance.
CloudFront is optimized to work with other Amazon Web Services, like Amazon S3, EC2, Elastic Load Balancer, and Route 53. Amazon CloudFront also works seamlessly with any non-AWS origin server, which stores the original, definitive versions of files.
Objects are cached for a period which is a TTL(Time to Live) i.e; 24 Hrs. Cached objects can be cleared, but you will be charged.
S3 Transfer Acceleration: Enables fast, easy and secure transfers of files over long distances between your end users and an S3 bucket. Transfer Acceleration takes advantage of Amazon CloudFront’s globally distributed edge locations. As the data arrives at an edge location, data is routed to Amazon S3 over an optimized network path.
AWS: DATABASES
RDS (RELATIONAL DATABASE SERVICE)

RDS is used for OLTP (Online Transaction Processing) workload.
OLTP processes data from transactions in real-time like customer orders, banking transactions, payments and booking systems.
Amazon RDS is available on several database instance types – optimized for memory, performance or I/O – and provides you with six familiar database engines to choose from, including Amazon Aurora, PostgreSQL, MySQL, MariaDB, Oracle Database, and SQL Server.
BENEFITS:
Easy to set up and operate: No need for infrastructure provisioning, and no need for installing and maintaining database software.
Highly scalable: Amazon RDS engine types allow you to launch one or more Read Replica to offload read traffic from your primary database instance.
Automatically backup and allows taking manual backup of the database as a snapshot.
FEATURES OF RDS
MULTI AZ:
Multi-AZ is an exact copy of the production database in another Availability Zone.
AWS handles the replication for you, so when your production database is written to the primary database in a particular AZ, then this write will automatically be synchronized to the standby database which is located in another AZ.
In the event of planned database maintenance, DB Instance failure, or an Availability Zone failure, Amazon RDS will automatically failover to the standby so that database operations can resume quickly without administrative intervention.
RDS type that can be configured as Multi-AZ: PostgreSQL, MySQL, MariaDB, Oracle Database, and SQL Server.
Multi-AZ is for Disaster Recovery only. It is not primarily used for improving performance. For performance improvement, you need a Read replica.
READ REPLICA:
Read replicas is a read-only copies of your primary database. This is achieved by using Asynchronous replication from the primary RDS instance to the read replica. You use read replicas primarily for a very read-heavy database workload and take the load off the primary database.
Read Replica can be located in the same AZ as the primary database. It can also be in cross AZ i.e; a completely different AZ, or it can even be in cross region, located in a completely different region.
Key Points:
Scaling Read Performance: Read replicas are used for scaling, not for disaster.
Require Automatic Backup: Must have automatic backups turned on in order to deploy a read replica.
Multiple Read Replica: MySQL, PostgreSQL, MariaDB, SQL and Oracle allow you to add up to 5 read replica copies of any database.
RDS Backups
- Automated Backups:
These are enabled by default. Allows you to recover your database to any point in time within a “retention period”. The retention period can be between 1 -35 days. Automated Backups will take a full daily snapshot and will also store transaction logs throughout the day. When you do a recovery, AWS will first choose the most recent daily backup, and then apply transaction logs relevant to that day. This allows you to do a point-in-time recovery down to a second, within the retention period.
Automated Backup is stored in S3 and you get free storage space equal to the size of your database.
2. Database Snapshots:
DB Snapshots are done manually (i.e; user-initiated). No retention period, manual snapshots are not deleted even after you delete the original RDS instance, including any automated backup. Provide a snapshot of the storage volume attached to the DB instance.
ELASTICACHE
Elasticache is an in-memory cache. This web service makes it easy to deploy, operate, and scale an in-memory cache in the cloud. The service improves the performance of web applications by allowing you to retrieve information from a fast in-memory cache, instead of relying entirely on a slower disk-based database.
Amazon ElastiCache can be used to significantly improve latency and throughput for many read-heavy application workloads (such as social networking, gaming, media sharing and Q&A portals) or compute-intensive workloads ( such as a recommendation engine). Caching improves application performance by storing critical pieces of data in memory for low-latency access.

Types of Elasticache:
Memcached: In-memory, key-value data store, Object caching is the primary goal. Scale horizontally, but there is no persistence, Multi-AZ or failover. Keep things as simple as possible.
Redis: In-memory, key-value data store. A more sophisticated solution with features like persistence, replication, Multi-AZ and failover. Support sorting and ranking data in memory such as leaderboards and also support more advanced data types, such as lists, hashes and sets. ElastiCache supports Master/Slave replication and Multi-AZ which can be used to achieve cross-AZ redundancy.
Elasticache is the best choice if the database is read-heavy and not prone to frequent changing. Elasticache will not help in alleviating heavy write loads, so you may need to scale up the database.
DynamoDB

Amazon DynamoDB is a fast and flexible NoSQL database service for all applications that need consistent, single-digit millisecond latency at any scale. It is a fully managed database and supports both document and key-value data models, Documents can be written in JSON, HTML or XML. Its flexible data model and reliable performance make it a great fit for mobile, web, gaming, ad tech, IoT and many other applications.
DynamoDB data stored in SSD (Solid State Desks) storage helps to give you consistently fast performance for reads and writes.
Spread Across 3 geographically distinct data centers to avoid failure.
Choice of 2 consistency models for DynamoDB read:
Eventual Consistent Reads (Default)
Strongly Consistent Reads
Eventually Consistent Reads:
Consistency across all copies of data across the 3 locations is usually reached within a second. Repeating a read after a short time should return the updated data. (Best Read Performance)
Strongly Consistent Reads:
A strongly consistent read returns a result that reflects all writes that received a successful response before the read.
DynamoDB Transactions
DynamoDB Transactions are to support mission-critical applications, which need an all-or-nothing approach to their database transactions.
ACID Transactions, ACID describes the ideal properties of a database transaction.
A: (Atomic) transaction is treated as a single unit.
C: (Consistent) means that it must be a valid transaction, it must leave the database in a valid state and that prevents any database corruption, or data integrity issues.
I: (Isolated) mean there is no dependency between different transactions, they are completed either in parallel or sequentially, effect going to be the same
D: (Durable) means that when a transaction has been committed, going to remain committed even after a system failure or a power loss, once it has been committed that means it’s going to be written to disk rather than being held in memory.
In short, the main idea is that transaction that possesses these qualities can be treated as a single operation on the data and the durability of the operation is guaranteed in the event of a system or power failure
Read or write multiple items across multiple tables as an all-or-nothing operation
Check for a pre-requisite condition before writing to a table
DynamoDB is made up of:
Tables
Items (a row of data in a table)
Attributes (a column of data in a table)
Supports key-value and document data structures.
Key = The name of the data, Value = the data itself.
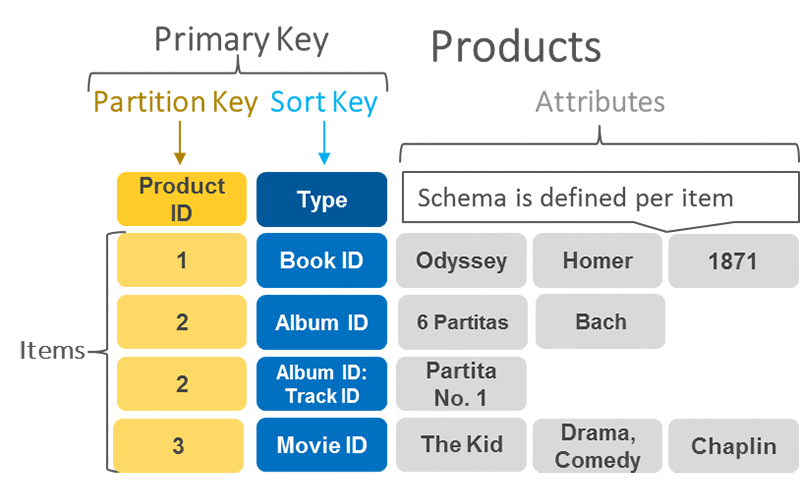
DynamoDB – Primary Keys
DynamoDB stores and retrieves data based on a Primary Key
2 Types of Primary Keys:
Partition Key: unique attribute (e.g. user ID)
The value of the Partition key is input to an internal hash function which determines the partition or physical location on which the data is stored.
If you are using the Partition Key as your Primary Key, then no two items can have the same Partition Key.
Composite Key (Partition Key + Sort Key): in combination (e.g. Same user posting multiple times to a forum
The primary key would be a Composite key consisting of a Partition Key – User ID, Sort Key- Timestamp of the post
2 items may have the same Partition Key, but they must have a different Sort Key.
All items with the same Partition Key are stored together, then sorted according to the sort key value.
Allows you to store multiple items with the same partition key.
Access Control
Authentication and Access Control are managed using AWS IAM.
You can create an IAM user within your AWS account which has specific permissions to access and create DynamoDB tables.
You can create an IAM role that enables you to obtain temporary access keys which can be used to access DynamoDB.
You can also use a special IAM Condition to restrict user access to only their records.
S3 (SIMPLE STORAGE SERVER)

Provides secure, durable, highly scalable object storage. Amazon S3 is easy to use, with a simple web services interface to store and retrieve any amount of data from anywhere on the web. This means S3 is a place to put flat files (not changing files) i.e; pictures, videos, and text files.
S3 is Object-based storage only — allows you to upload files, images, documents, videos, and code. It cannot be used to run an operating system or database.
The basics of S3 are:
Object size can be from 0 Bytes to 5TB.
Unlimited Storage: Total volume of data and the number of objects you can store is unlimited
Files are stored in Buckets.
S3 is a universal namespace. That is, names must be unique globally. Ex: https://bucket-name.s3.eu-west-1.amazonaws.com/image1.jpg
When you upload a file to S3, you will receive an HTTP 200 code if the upload was successful.
S3 is a safe place to store files. The data is spread across multiple devices and facilities to ensure availability and durability.
CHARACTERISTICS:
Tiered Storage: Offers a range of storage classes designed for different use cases.
Lifecycle Management: Define a rule to automatically transition objects to a cheaper storage tier or delete objects that are no longer required after a set period.
Versioning: All versions of an object are stored and can be retrieved, including deleting objects.
S3 Storage Classes
S3 Standard: 99.99% availability, 99.9999..% durability(11 9’s), stored redundantly across multiple devices in multiple facilities(>=3 AZs), and is designed to sustain the loss of 2 facilities concurrently. Best for websites, mobile and gaming applications and big data analytics.
S3 – IA (Infrequently Accessed): For data that is accessed less frequently, but requires rapid access when needed. Lower fee for per GB storage and a per GB retrieval fee. Great for long-term storage and backups.
S3 One Zone – IA: For where you want a lower–cost option for infrequently accessed data, but data is stored redundantly within a single AZ.
S3- Intelligent Tiering: Designed to optimize costs by automatically moving data to the most cost-effective access tier, without performance impact or operational overhead.
S3 Glacier: This is a secure, durable, and low-cost storage class for data archiving. You can reliably store any amount of data at costs that are competitive with or cheaper than on-premises solutions. Retrieval times are configurable from minutes to hours.
S3 Glacier Deep Archive: S3 Glacier Deep Archive is Amazon S3’s lowest-cost storage class where a retrieval time of 12 hours is acceptable e.g., financial records that may be accessed once or twice per year.
EBS(ELASTIC BLOCK STORE) VOLUME

EBS is a highly available and scalable storage volume or disk that can be attached to EC2 instances. You can create a file system on top of these volumes, or use them in any way you would use a block device (such as a hard drive). You can dynamically change the configuration of a volume attached to an instance. With Amazon EBS, you pay only for what you use.
Features of EBS:
Scalable: Dynamically increase capacity and change the type volume with no downtime or performance impact on your live systems.
Designed for mission-critical workloads.
Highly Available: Automatically replicated within a single availability zone to protect against hardware failures.
EBS Volume Types
- General Purpose SSD (gp2):
Get a balance of price and performance
3 IOPS (IO operation per second) per GiB, up to a max of 16,000 IOPS per volume.
gp2 volumes < 1TB can be burst up to 3,000 IOPS.
Great for boot vol or development and test applications which are not latency sensitive.
- Provisioned IOPS SSD (io1):
High performance and the most expensive option.
Up to 64,000 IOPS per vol, 50 IOPS per GiB.
Use if you need more than 16,000 IOPS, up to 99.9% durability.
Designed for I/O intensive applications, large databases, and latency-sensitive workloads.
Suitable for OLTP (Online transaction processing)
- Provisioned IOPS SSD (io2):
The latest generation of Provisioned IOPS
Higher durability and more IOPS per GiB (500 IOPS/GiB), Up to 64,000 IOPS per vol
99.999% durability
- Throughput Optimized HDD (st1):
Baseline throughput of 40 MB/s per TB
Ability to burst up to 250 MB/s per TB.
Maximum throughput of 500 MB/s per vol
Used for frequently-accessed, throughput-intensive workloads.
Big Data, data warehouse, ETL(Extract Transform Load operations) and log processing.
A cost-effective way to store mountains of data.
Cannot be a boot volume.
- COLD HDD (sc1)
Lowest cost option.
Baseline throughput of 12 MB/s per TB.
Ability to burst up to 80 MB/s per TB.
Max throughput of 250 MB/s per vol.
Good for data that requires fewer scans per day (Less-Frequently-accessed data).
Good for applications that need the lowest cost and performance is not a factor.
Cannot be a boot vol.
API GATEWAY
API (Application Programming Interface), API is used to interact with web applications, and applications use APIs to communicate with each other. API Gateway has cashing capabilities to increase performance.
It is a fully managed service that makes it easy for developers to publish, maintain, monitor and secure APIs at any scale. APIs act as a “front door” for applications to access data, business logic, or functionality from your back-end services, such as applications running on EC2, code running on AWS Lambda, or any web application. This service provides a single endpoint for all client traffic interacting with the backend of your application.
Types of API
REST APIs (REpresentational State Transfer): Used by 70% of the internet. It is going to use JSON (Key value pair). This api is optimized for stateless, serverless workloads.
Websocket APIs are for real-time, two-way, stateful communication example chat apps.
Key Points:
API Gateway is serverless therefore it is low in cost and scales automatically.
Supports throttling: Throttle API Gateway to prevent your application from being overloaded by too many requests.
Logged to CloudWatch examples of API calls, latencies and errors.
Maintain multiple versions of API.
STEP FUNCTION

Step Functions allows you to visualize and test your serverless applications. Step functions provide a graphical console to arrange and visualize the components of your application as a series of steps. This makes it simple to build and run multi-step applications. Step functions automatically trigger and tracks each step, and retires when there are errors, so your application executes in order and as expected. Step functions log the state of each step so that when things do go wrong, you can diagnose and debug problems quickly.

Key Points:
Great way to visualize your serverless application.
Step functions automatically trigger and track each step.
Step functions log the state of each step so if something goes wrong you can track what went wrong and where.
X-RAY
An X-Ray is a tool that helps developers analyze and debug distributed applications. Allowing you to troubleshoot the root cause of performance issues and errors. Provided with the service map which is a visual representation of the application
AWS X-Ray is a service that collects data about requests that your application serves and provides tools you can use to view, filter and gain insights into that data to identify issues and opportunities for optimization. For any traced request to your application, you can see detailed information not only about the request and response but also about calls that your application makes to downstream AWS resources, microservices, databases and HTTP web APIs.
The X-Ray Integrates with the following AWS services:
Elastic Load Balancer
AWS Lambda
Amazon API Gateway
Amazon EC2
AWS Elastic Beanstalk
SNS
SQS
DynamoDB
X-Ray Languages:
Java
Go
Node.js
Python
Ruby
.Net
X-Ray Architecture
X-Ray SDK automatically captures metadata for API calls made to AWS services using the AWS SDK.
We have an X-Ray SDK installed inside the application and this SDK sends bits of JSON to the X-Ray Daemon, and this Daemon installs on the Linux PC, and Windows PC. X-Ray Daemon takes JSON and sends it to the X-Ray API, X-Ray API stores all the data. We also have Scripts and Tools, these are normal SDKs and CLI that communicate with the X-Ray Daemon and X-Ray API directly.
X-Ray Daemon
It is an application that listens for traffic on the port
Open source project.
Lambda and Elastic Beanstalk can use X-Ray Daemon.
Run X-Ray daemons on AWS as well as in an on-premises environment.
X-Ray SDK provides:
Interceptors to add to your code to trace incoming HTTP requests.
Client handlers to instrument AWS SDK clients that your application uses to call other AWS services
An HTTP client to use to instrument calls to other internal and external HTTP web services
Key Points:
Help you to analyze and debug applications.
Create a service map of the services used by the application.
Identify the bugs and error in your application and automatically highlights them.
Thank you for joining me this far. I hope that my notes on AWS have provided you with a valuable introduction and saved some time. I look forward to sharing more of my notes with you in the future. Until next time, happy cloud computing!"




