Introduction to TimescaleDB for Algorithmic Trading

In algorithmic trading, you often retrieve data once from web services (data provider) and use it multiple times to back-test multiple strategies. The tick data is used again and again hundreds of times for different transformations (like aggregations, creating candles in real time) in backtesting of trading strategies You can obviously store in-memory data on disk in CSV format however as data grow, you need a database to cut out a significant amount of latency. As the nature of data requires almost no update, only Insert and Select statements multiple times, we should use a database that is optimized for this purpose. Here comes the time series databases.
What is a time series database?
A time series database (TSDB) is a database optimized for storing and serving time series data. Time series data is data that is collected over time, such as financial market data, logs, monitoring data, and weather data. TSDBs are designed to make it easy to store, query, and analyze time series data.
Examples of Time series databases
InfluxDB: InfluxDB is an open-source time series database that is designed for high performance and scalability. It is used by a variety of organizations, including Uber, Twitch, and Yelp.
Prometheus: Prometheus is an open-source monitoring system and time series database that is used by a variety of organizations, including Google, Facebook, and Netflix.
TimescaleDB: TimescaleDB is an open-source time series database that is based on PostgreSQL. It provides the performance and scalability of a traditional database with the flexibility and features of a time series database.
DolphinDB: DolphinDB is a commercial time series database that is designed for high performance and scalability. It is used by a variety of organizations, including Goldman Sachs, Morgan Stanley, and IBM.
RRDTool: RRDTool is an open-source tool for storing and graphing time series data. It is often used for monitoring systems and network traffic analysis.
OpenTSDB: OpenTSDB is an open-source time series database that is based on HBase. It is used by a variety of organizations, including Twitter, Facebook, and Yahoo.
TimescaleDB: Postgres for time-series
TimescaleDB is an open-source relational database that extends PostgreSQL with time-series capabilities. TimescaleDB allows developers and organizations to store, query, and analyze time-series data at scale. It also includes features such as automatic data partitioning, advanced indexing for time-series queries, and support for SQL and native time-series functions.
How to install Timescale DB?
The easiest way is to install using Docker. If you are using Windows, you need to install the docker desktop that would get installed in System Drive (C drive). It will create 2 distros docker-desktop and docker-desktop-data. You can see this at %LOCALAPPDATA%/Docker/wsl; and inside you will find vhdx file. If you are running low on System drive space, you can move docker-desktop-data out to another drive.
wsl --shutdown
wsl --export docker-desktop-data D:\docker-desktop\docker-desktop-data.tar
wsl --unregister docker-desktop-data
wsl --import docker-desktop-data D:\docker-desktop\data D:\docker-desktop\docker-desktop-data.tar --version 2
More detail on this can be found on this page.
You can install a TimescaleDB instance from a pre-built container.
Run the docker image: The TimescaleDB HA Docker image includes Ubuntu as its operating system.
docker pull timescale/timescaledb-ha:pg14-latestRun the image from the container
docker run -d --name timescaledb -p 5432:5432 -e POSTGRES_PASSWORD=password timescale/timescaledb-ha:pg14-latestdocker start timescaledb # To start docker container docker stop timescaledb # To stop docker container
You can use pgAdmin to connect to this container and create tables accordingly.
- Install / Open pgAdmin and add a new server
Provide the hostname, port, database, username and password to connect to the instance running on the docker container.
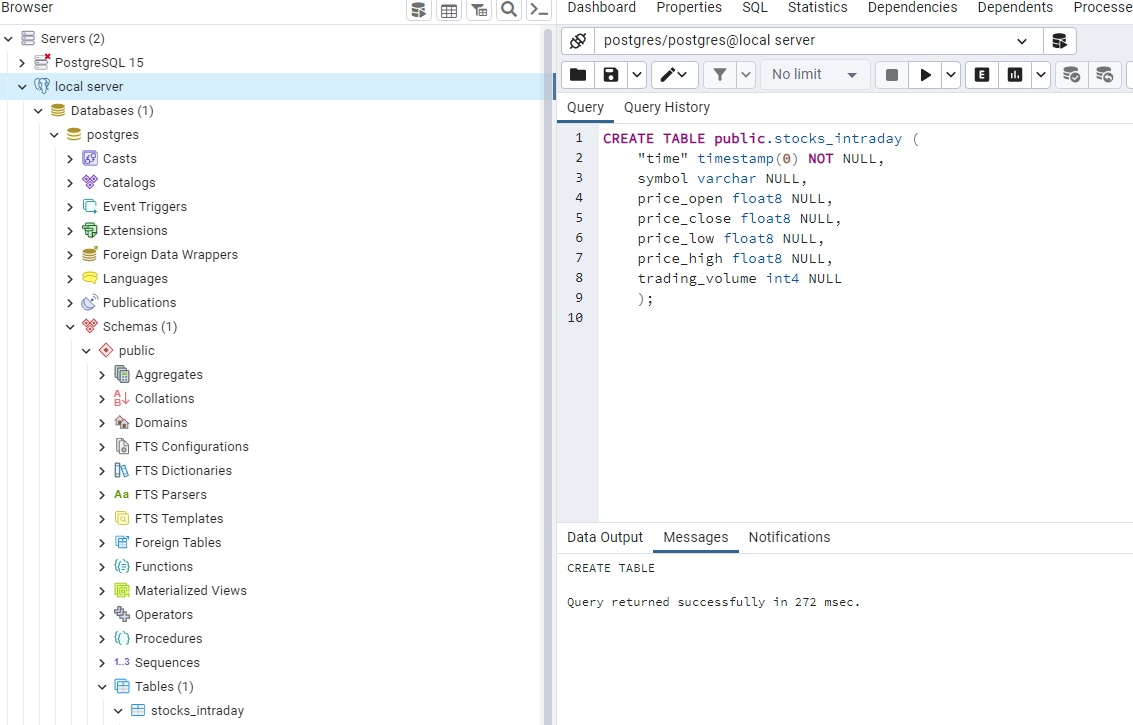
You can just use SQL queries like creating a table by executing the SQL query below. You don't need to learn any other structured query language to work with Timescaledb, unlike Influxdb.
However, we will of course use Python to connect with Timescaledb using psycopg2 and sqlalchemy.
Connect from Python using Psycopg2
Psycopg2 is the most loved PostgreSQL database adapter for Python, hence worked with TimescaleDB. It was designed for heavily multi-threaded applications that create and destroy lots of cursors and make a large number of concurrent “INSERT”s or “UPDATE”s.
pip install psycopg2-binary
import psycopg2
# Create connection
con = psycopg2.connect(
host = 'hostname'
database ='dbname',
user = 'postgres',
password = 'password')
# Create cursor
cur = con.cursor()
# SQL
query = 'INSERT INTO stock_intraday (time,symbol,price_open,price_close,
price_low,price_high,trading_volume VALUES (%s,%s,%s,%s,%s,%s,%s)'
record =(time,symbol,price_open,price_close,
price_low,price_high,trading_volume)
cur.execute(query,record)
#commit
con.commit()
#close the connection
con.close()
Ingest Pandas Dataframe to TimescaleDB
There are multiple ways to ingest data into our database, however, I want to discuss quickly the simplest and probably the slowest using sqlalchemy. Let's say you have a DataFrame df as below. We can create and insert DataFrame using to_sql:
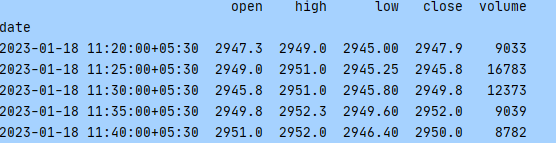
from sqlalchemy import create_engine
engine = create_engine('postgresql://postgres:pwd@localhost:5432/postgres')
df.to_sql('abc', con=engine, if_exists = 'replace',index =True)
A table gets created based on the data frame with the datatype supported by TimescaleDB.
# reading the table from the db
query = "SELECT * FROM " + table_name
df = pd.read_sql_query(query, engine)
Features of TimescaleDB
At least these feature two worth mentioning here:
Hypertables
Hypertables are PostgreSQL tables that automatically partition your data by time. With hypertables, Timescale makes it easy to improve insert and query performance by partitioning time-series data on its time parameter. Behind the scenes, the database performs the work of setting up and maintaining the hypertable's partitions. Each hypertable is made up of child tables called chunks. Each chunk is assigned a range of time, and only contains data from that range.
Continuous aggregates
If you are collecting tick data, e.g. several stock prices per seconds, you might want to aggregate your data into 1 minute, 5 minute or 1-hour instead, with open, close, high, and low candles. Continuous aggregates take raw tick data from the original hypertable, aggregate it, and store the intermediate state in a materialization hypertable. Continuous aggregate views are refreshed automatically in the background as new data is added. Timescale tracks these changes to the dataset and automatically updates the view in the background.
Conclusion
While working with stock data, you can store it in flat files such as CSV, HDFStore object or SQLite. As you start working with thousands of stock prices and with multi-year data (e.g. 5 mins or 15 mins candles) you need to store the time series in the databases. You can transfer several calculations and transformations to the server side where it is most suited. TimescaleDB is the natural choice as it is open source, an extension of PostgreSQL, and supports SQL with native support for time series.
Happy Trading!




