Design Patterns in Rust with Algorithmic Trading Examples
What is design?
“Design” as a word is both an activity (verb) and a product (noun). As a verb it’s the process of thinking through and creating blueprints for classes, architectures, or systems. Design as a Noun is the artifact that results from the design activity. It might be a blueprint for a class, a system’s architectural diagram, or an entire ecosystem of interacting components.
When we talk about “design,” we’re not just envisioning static documents or diagrams; we’re imagining a dynamic ecosystem, much like a pond where water flows through pipes, where fish of different species interact, and where various environmental factors maintain a stable balance. A well-designed software system similarly has multiple components—classes, modules, services, or patterns—that function together harmoniously, each constrained by and supportive of the larger architecture. Similarly software design imposes conditions on components, dictating how they can or cannot interact.
In object-oriented software design, design patterns are like ecological rules or best practices that address common problems and encourage stable interactions:
Creational Patterns: Provide ways to instantiate objects
Structural Patterns: Arrange classes and objects
Behavioral Patterns: Govern how objects communicate and respond
While design patterns solve localized design issues, software architecture design looks at the macro-level:
Layered Architectures: Separate responsibilities into layers
Service-Oriented or Microservices: Break the system into independent yet interacting services
Event-Driven Architectures: Focus on asynchronous communication and flows
Why Emphasize Design?
Maintainability: A thoughtful design is easier to extend and adapt.
Scalability: Well-chosen architectural decisions can accommodate growing demands without fundamental redesign.
Reusability: Components, once designed, can be repurposed in future projects or domains.
Predictability: Like a stable ecosystem, a well-architected system exhibits predictable behaviors, simplifying testing and debugging.
The main focus of this blog is design patterns using object oriented concepts.
What is Algorithmic Trading?
Algorithmic trading models are automated trading strategies that use predefined rules, instructions and quantitative techniques to execute trades in financial markets. These are highly quantitative process used by large financial institutions. Now when technology touches every part of our lives, it's no surprise that algorithmic trading, once only used by big firms, is now available to individual traders and investors. This democratization has created many opportunities, but it also brings challenges and risks. This section will introduce you to algorithmic trading.
As executing large buy or sell order will push the price higher or lower that is also a cost for the firm. This cost associated with this is market impact cost. The algorithmics that aim to minimize the market impact cost along with other execution cost such as bid-ask spread are called order execution algorithms.
The algorithmic trading / systematic trading firms called buy-side develop algorithms / models aim to capitalize on market inefficiencies, trends or patterns to generate trading signals by analyzing vast amounts of data. There are also market making firms (called sell-side) that use trading strategy to foster market liquidity by continuously quoting both bid and ask prices for a specific security, effectively creating a two-way market. By actively participating in the market, market markers profit from the bid-ask spread and rebates.
At the heart of an algorithmic trading system are several essential components, including Order Management Systems (OMS), Execution Management Systems (EMS), backtesting frameworks and many more. Before exploring the design patterns, let's take a moment to discuss these components briefly to gain a better understanding of the design pattern examples. In addition to the algorithmic trading components, we will also cover essential terms related to the trading system. In this blog, as we implement various design pattern, we will learn Rust core concepts, data structures and algorithmic trading concepts.
Order management systems (OMS)
Order management systems (OMS) play a crucial role in monitoring and executing trades for clients, such as portfolio managers and traders. For instance, when a portfolio manager decides to purchase 5,000 shares of NVDA at a limit price of $130 per share, they enter this order into the OMS. The OMS checks whether the order violates fund's concentration limit and if it does then alerts the PM. If all okay then analyzes current market conditions and routes the order to an exchange where the likelihood of execution at the desired price is highest. After execution, OMS sends trade details to the back-office system.
It's impressive how OMS can manage such high volumes of orders from various sources, control the flow, validate them, and ensure that trades are completed both efficiently and accurately.
Order Execution Algorithms
Arrival Price (Implementation Shortfall)
The arrival price will attempt to achieve, over the course of the order, the bid/ask midpoint price at the time the order is submitted. The arrival algo keeps the hidden orders that will impact a high percentage of the average daily volume.
Accumulate / Distribute
This algo achieve the best price for a large volume order without being noticed in the market, and can be set up for high frequency trading by slicing the order into smaller randomly sized order increments that are released at random time intervals within a used defined time period.
TWAP (Time Weighted Average Price)
TWAP algorithms are designed to execute trades based on a rate proposed to time. It aims to achieve the time weighted average price calculated from the time of submitted order to the time it completes.
VWAP (Volume Weighted Average Price)
VWAP algo seeks to achieve the volume weighted average price, calculated from the time of submitted order. VWAP schedule is proportional to the historical intraday volume profile. This algo trade more at some time frame when the stock traded more historically at same time frame.
Percentage of Volume
The POV is an order execution trading strategy that allows trades to execute the desired percentage of the total market volume called participation rate over a specified period. It’s an adaptive strategy designed to adjust the order size dynamically based on prevailing or forecasted market volume in real-time.
The SOLID Design Principles
Let's review the SOLID design principles since we might mention them while discussing design patterns. It's helpful to remember these principles when designing maintainable and scalable object-oriented systems.
Single Responsibility Principle (SRP): A class should have only one reason to exist, meaning it should have only one job or responsibility. You should not overload your objects with two many responsibility, just create a new class for it.
Open/Closed Principle (OCP): Software entities (classes, modules, functions, etc.) should be open for extension but closed for modification. This means you should be able to add new functionality without changing existing code.
Liskov Substitution Principle (LSP): Objects of a superclass should be replaceable with objects of a subclass without affecting the correctness of the program. This ensures that a subclass can stand in for its superclass.
Interface Segregation Principle (ISP): Clients should not be forced to depend on interfaces they do not use. This means creating smaller, more specific interfaces rather than a large, general-purpose one.
Dependency Inversion Principle (DIP): High-level modules should not depend on low-level modules. Both should depend on abstractions. Additionally, abstractions should not depend on details. Details should depend on abstractions. This principle helps in reducing the coupling between different parts of a system.
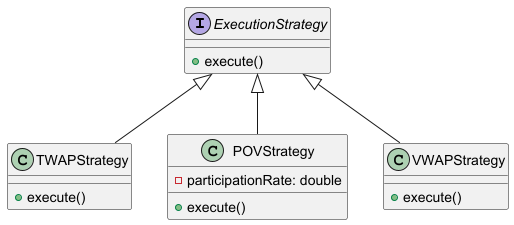
🔍Strategy Pattern
The Strategy design pattern is a behavioral design pattern that enables selecting an algorithm's behavior at runtime. This pattern is based on composition. Lets see the definition from the “Head First Design Pattern”:
The strategy pattern defines a family of algorithms, encapsulates each one, and makes them interchangeable. Strategy lets algorithm vary independently from clients that use it.
It is naturally useful in trading systems where algorithms need to switch between different execution methods. In this example, we'll implement a simplified trading system in Rust that executes orders using different strategies like TWAP (Time-Weighted Average Price), VWAP (Volume-Weighted Average Price), and POV (Percentage of Volume). These are your execution strategies. You can choose one of the strategies based on certain factors or constraints.
Structure
- The Strategy interface is common to all concrete strategies. It declares a method the context uses to execute a strategy. We define a common interface for all execution strategies, the method
execute_orderthat all execution strategies must implement.
trait ExecutionStrategy {
fn execute_order(&self, order_id: u32, quantity: u32);
}
Concrete Strategies implement different variations of an algorithm the context uses. In this example, we write implementations of TWAP, VWAP, and POV strategies.
struct TwapStrategy; impl ExecutionStrategy for TwapStrategy { fn execute_order(&self, order_id: u32, quantity: u32) { println!("Executing order {} using TWAP for {} units.", order_id, quantity); // Implement TWAP logic here } } struct VwapStrategy; impl ExecutionStrategy for VwapStrategy { fn execute_order(&self, order_id: u32, quantity: u32) { println!("Executing order {} using VWAP for {} units.", order_id, quantity); // Implement VWAP logic here } } struct PovStrategy { participation_rate: f64, } impl ExecutionStrategy for PovStrategy { fn execute_order(&self, order_id: u32, quantity: u32) { println!( "Executing order {} using POV at {}% participation for {} units.", order_id, self.participation_rate * 100.0, quantity ); // Implement POV logic here } }The Context maintains a reference to one of the concrete strategies and communicates with this object only via the strategy interface. Here we write the
OrderExecutorthat holds a reference to a strategy and uses it to execute orders. The context calls the execution method on the linked strategy object each time it needs to run the algorithm. The context doesn’t know what type of strategy it works with or how the algorithm is executed.struct OrderExecutor { strategy: Box<dyn ExecutionStrategy>, } impl OrderExecutor { fn new(strategy: Box<dyn ExecutionStrategy>) -> Self { OrderExecutor { strategy } } fn set_strategy(&mut self, strategy: Box<dyn ExecutionStrategy>) { self.strategy = strategy; } fn execute(&self, order_id: u32, quantity: u32) { self.strategy.execute_order(order_id, quantity); } }The Client creates a specific strategy object and passes it to the context. The context exposes a setter which lets clients replace the strategy associated with the context at runtime.
fn main() { let order_id = 101; let quantity = 1000; // Using TWAP Strategy let twap_strategy = Box::new(TwapStrategy); let mut executor = OrderExecutor::new(twap_strategy); executor.execute(order_id, quantity); // Switching to VWAP Strategy let vwap_strategy = Box::new(VwapStrategy); executor.set_strategy(vwap_strategy); executor.execute(order_id+1, quantity); // Switching to POV Strategy let pov_strategy = Box::new(PovStrategy { participation_rate: 0.1, }); executor.set_strategy(pov_strategy); executor.execute(order_id+2, quantity); }

Strategy pattern Class Diagram

👀Observer Pattern
The Observer design pattern is a behavioral design pattern that enables an object, known as the Subject, to maintain a list of its dependents, called Observers, and automatically notify them of any state changes, typically by calling one of their methods. This pattern is particularly useful in Event-Driven Systems, when you need to notify multiple objects about events without tightly coupling them. The definition from the “Head First Design Pattern”:
The observer pattern defines a one to many dependency between objects so that when one object changes state, all of its dependents are notified and updated automatically.
In the context of algorithmic trading , the Observer pattern can be applied to scenarios such as:
Market Data Feeds: Notifying trading strategies when new market data arrives.
Order Execution Updates: Informing interested parties when an order is executed or its status changes.
Price Alerts: Triggering alerts when certain price thresholds are crossed.
Structure
Subject (Observable or Publisher): The Subject issues events of interest to other objects. These events occur when the subject (publisher) changes its state or executes some behaviors. Subjects maintain a subscription infrastructure, list of observers and provides methods to attach, detach, and notify them.
Observer (Subscriber): The Observer interface declares the notification interface. In most cases, it consists of a single
updatemethod.Concrete Subject: Implements the subject interface and holds the state of interest.
Concrete Observer: Concrete Observer perform some actions in response to notifications issued by the subject. All of these classes must implement the same interface so the subject isn’t coupled to concrete classes.
Usually, subscribers need some contextual information to handle the update correctly. For this reason, publishers often pass some context data as arguments of the notification method. The publisher can pass itself as an argument, letting subscriber fetch any required data directly.
Implementation Example
We will implement a simplified version of trading system using Rust where we have:
Market Data Feed (Subject): Provides live price updates for various financial instruments.
Trading Strategies (Observers): React to market data updates to make trading decisions.
Let's take a look at the UML diagram of this example and code implementation.
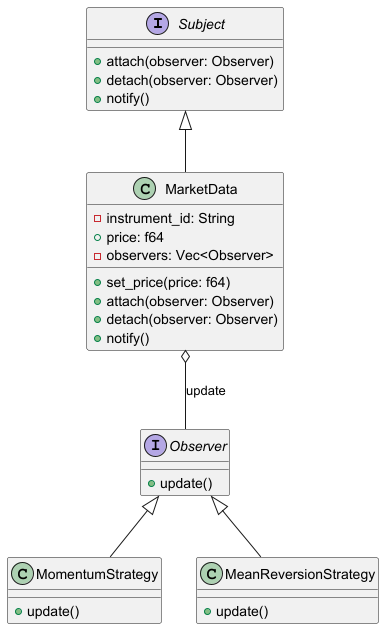
Observer Trait
The Observer trait declares the update method, which observers must implement.
use std::rc::Rc;
use std::cell::RefCell;
trait Observer {
fn update(&self, instrument_id: &str, price: f64);
}
Implement Concrete Observers (Trading Strategies)
struct MomentumStrategy {
name: String,
threshold: f64,
}
impl Observer for MomentumStrategy {
fn update(&self, instrument_id: &str, price: f64) {
if price > self.threshold {
println!(
"{}: [{}] Price crossed above threshold! Price: {}",
self.name, instrument_id, price
);
// Implement buy logic
} else {
println!(
"{}: [{}] Price below threshold. Price: {}",
self.name, instrument_id, price
);
// Implement hold or sell logic
}
}
}
struct MeanReversionStrategy {
name: String,
average_price: RefCell<f64>,
}
impl Observer for MeanReversionStrategy {
fn update(&self, instrument_id: &str, price: f64) {
let mut avg = self.average_price.borrow_mut();
*avg = (*avg * 0.9) + (price * 0.1); // Update moving average
if price < *avg {
println!(
"{}: [{}] Price below average! Price: {}, Average: {:.2}",
self.name, instrument_id, price, *avg
);
// Implement buy logic
} else {
println!(
"{}: [{}] Price above average. Price: {}, Average: {:.2}",
self.name, instrument_id, price, *avg
);
// Implement sell logic
}
}
}
Define the Subject Trait
trait Subject {
fn attach(&mut self, observer: Rc<dyn Observer>);
fn detach(&mut self, observer: &Rc<dyn Observer>);
fn notify(&self);
}
Implement the Concrete Subject (Market Data Feed)
struct MarketDataFeed {
instrument_id: String,
observers: RefCell<Vec<Rc<dyn Observer>>>,
price: RefCell<f64>,
}
impl MarketDataFeed {
fn new(instrument_id: &str) -> Self {
MarketDataFeed {
instrument_id: instrument_id.to_string(),
observers: RefCell::new(Vec::new()),
price: RefCell::new(0.0),
}
}
fn set_price(&self, new_price: f64) {
*self.price.borrow_mut() = new_price;
self.notify();
}
}
impl Subject for MarketDataFeed {
fn attach(&mut self, observer: Rc<dyn Observer>) {
self.observers.borrow_mut().push(observer);
}
fn detach(&mut self, observer: &Rc<dyn Observer>) {
let mut observers = self.observers.borrow_mut();
if let Some(pos) = observers.iter().position(|x| Rc::ptr_eq(x, observer)) {
observers.remove(pos);
}
}
fn notify(&self) {
let price = *self.price.borrow();
let instrument_id = &self.instrument_id;
for observer in self.observers.borrow().iter() {
observer.update(instrument_id, price);
}
}
}
Client Code
fn main() {
// Create market data feed for AAPL
let mut market_data_feed = MarketDataFeed::new("AAPL");
// Create observers
let momentum_strategy: Rc<dyn Observer> = Rc::new(MomentumStrategy {
name: String::from("MomentumStrategy"),
threshold: 150.0,
});
let mean_reversion_strategy: Rc<dyn Observer> = Rc::new(MeanReversionStrategy {
name: String::from("MeanReversionStrategy"),
average_price: RefCell::new(145.0),
});
// Attach observers
market_data_feed.attach(momentum_strategy.clone());
market_data_feed.attach(mean_reversion_strategy.clone());
// Simulate market data updates
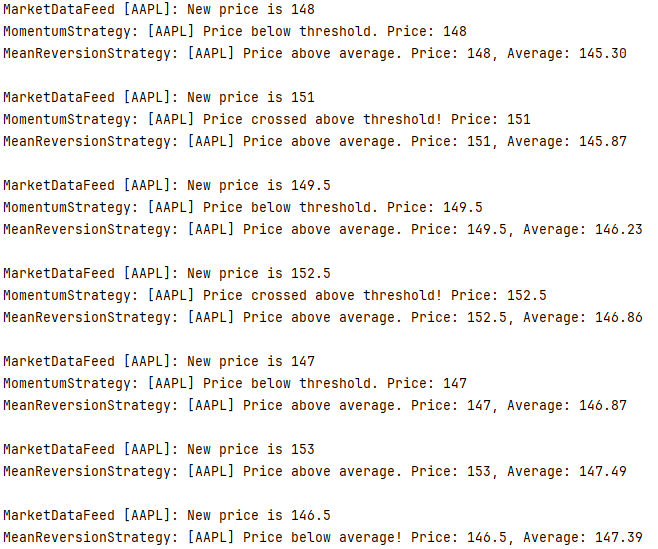
let price_updates = vec![148.0, 151.0, 149.5, 152.5, 147.0];
for price in price_updates {
println!("\nMarketDataFeed [{}]: New price is {}", "AAPL", price);
market_data_feed.set_price(price);
}
// Detach momentum strategy
market_data_feed.detach(&momentum_strategy);
// More updates
let more_price_updates = vec![153.0, 146.5];
for price in more_price_updates {
println!("\nMarketDataFeed [{}]: New price is {}", "AAPL", price);
market_data_feed.set_price(price);
}
}
Notes on Rust Implementation
Reference Counting (
Rc): Used to allow multiple ownership of observers by the subject.Interior Mutability (
RefCell): Allows us to mutate data even when it is wrapped in an immutable reference, which is necessary when observers need to update their internal state upon receiving updates.Trait Objects (
dyn Trait): Trait objects likedyn Observerallow for dynamic dispatch in Rust. They allow the subject to hold a collection of different types that implement the same trait.
In Rust, comparing trait objects (dyn Observer) directly is not straightforward because trait objects do not implement PartialEq by default. We use Rc::ptr_eq to compare the pointers of the Rc smart pointers, which checks if they point to the same allocation.
In the line, if we don’t explicitly say the type Rc<dyn Observer> then momentum_strategy will be of type Rc<MomentumStrategy> and it will be fine for attach method however not work with detach method.
let momentum_strategy: Rc<dyn Observer> = Rc::new(MomentumStrategy{...});
In Rust, even though MomentumStrategy implements the Observer trait, Rc<MomentumStrategy> and Rc<dyn Observer> are different types and are not directly interchangeable.
💡Note: The Rc::ptr_eq function requires that both Rc pointers have the same type parameter. By ensuring that both Rc pointers are of type Rc<dyn Observer>, we satisfy this requirement.
Rust can automatically coerce a reference to a concrete type into a reference to a trait object if the type implements the trait. This is what happens when you assign Rc::new(MomentumStrategy { /* fields */ }) to a variable of type Rc<dyn Observer>.
Decorator Pattern
The Decorator Pattern is a structural design pattern that allows behavior to be added to individual objects dynamically without affecting the behavior of other objects from the same class. The definition from the “Head First Design Pattern”:
The decorator pattern attaches additional responsibilities to an object dynamically. Decorators provides a flexible alternative to subclassing for extending functionality.
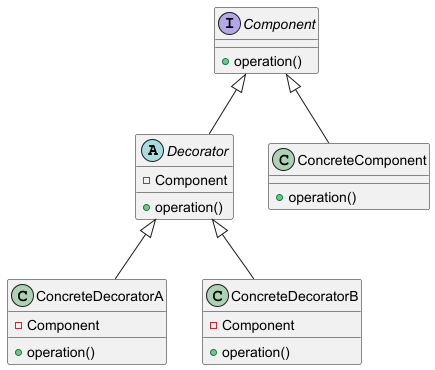
Structure
Component Interface: Defines the interface for objects that can have responsibilities added to them dynamically.
Concrete Component: The original object to which additional responsibilities are added.
Decorator: Abstract class that implements the component interface and contains a reference to a component object.
Concrete Decorators: Extend the functionality of the component by overriding methods and adding additional behaviors.
UML Diagram
Example: Enhancing Order Execution with Decorators
We have an OrderExecutor component responsible for executing trades. We want to add additional behaviors:
LoggingDecorator: Logs the details of each order execution.
ValidationDecorator: Validates orders before execution.
Component Trait
#[derive(Debug)]
struct Order {
symbol: String,
quantity: i32,
price: f64,
}
trait OrderExecutor {
fn execute_order(&self, order: &Order) -> Result<(), String>;
}
Concrete Component
struct BasicOrderExecutor;
impl OrderExecutor for BasicOrderExecutor {
fn execute_order(&self, order: &Order) -> Result<(), String> {
// Simulate order execution logic
println!("Executing order: {:?}", order);
Ok(())
}
}
Concrete Decorators
struct LoggingDecorator<T: OrderExecutor> {
execu
tor: T,
}
impl<T: OrderExecutor> LoggingDecorator<T> {
fn new(executor: T) -> Self {
LoggingDecorator { executor }
}
}
impl<T: OrderExecutor> OrderExecutor for LoggingDecorator<T> {
fn execute_order(&self, order: &Order) -> Result<(), String> {
println!("LoggingDecorator: Order received: {:?}", order);
let result = self.executor.execute_order(order);
println!("LoggingDecorator: Order execution result: {:?}", result);
result
}
}
struct ValidationDecorator<T: OrderExecutor> {
executor: T,
}
impl<T: OrderExecutor> ValidationDecorator<T> {
fn new(executor: T) -> Self {
ValidationDecorator { executor }
}
}
impl<T: OrderExecutor> OrderExecutor for ValidationDecorator<T> {
fn execute_order(&self, order: &Order) -> Result<(), String> {
if self.validate(order) {
println!("Validated Order: {:?}", order);
self.executor.execute_order(order)
} else {
Err(String::from("Validation failed"))
}
}
}
impl<T: OrderExecutor> ValidationDecorator<T> {
fn validate(&self, order: &Order) -> bool {
// Implement validation logic
order.quantity > 0 && order.price > 0.0
}
}
Client Code
fn main() {
let order = Order {
symbol: String::from("AAPL"),
quantity: 100,
price: 150.0,
};
// Basic executor
let basic_executor = BasicOrderExecutor;
// Decorate with validation
let validated_executor = ValidationDecorator::new(basic_executor);
// Further decorate with logging
let logged_executor = LoggingDecorator::new(validated_executor);
// Execute the order
let result = logged_executor.execute_order(&order);
match result {
Ok(_) => println!("Order executed successfully."),
Err(e) => println!("Order execution failed: {}", e),
}
}

Notes on Rust Implementation
In this example, I used generics allowing static dispatch. By the way, in Rust, traits are not types themselves; they are a collection of methods that types can implement. You cannot instantiate a trait directly or store it as a field without using a pointer or a generic parameter. The following will result in compilation error because OrderExecutor is a trait.
struct ValidationDecorator {
executor: OrderExecutor,
}
In Rust, all types must have a known size at compile time unless they are behind a pointer (like &, Box, or Rc) or used as a generic type parameter with trait bounds. By default, all generic type parameters and struct fields have an implicit Sized bound. This means that the compiler needs to know the size of the type at compile time.
The choice between generics and trait objects depends on your specific needs for performance and flexibility.
Instead of generics, you can use Trait Objects as follows:
struct ValidationDecorator {
executor: Box<dyn OrderExecutor>,
}
This uses dynamic dispatch, which introduces a slight runtime overhead due to the use of a vtable.
🏭Factory Method Pattern
Factory Method is a creational design pattern that provides an interface for creating objects in a superclass, but allows subclasses to alter the type of objects that will be created. This definition is by the refactoring.guru. The “Head First Design Pattern” more or less says the same:
The Factory Method Patterns defines an interface for creating an object, but lets subclasses decide which class to instantiate. Factory method lets a class defer instantiation to subclasses.
Structure
Product Interface: Defines the interface of objects the factory method creates.
Concrete Products: Various implementations of the product interface.
Creator (Factory): Declares the factory method that returns new product objects.
Concrete Creators: Override the factory method to change the resulting product's type.
Example: Order Creation Factory
Let's consider an example where we need to create different types of orders based on the current state of our trading strategy.
Order Types
Market Order: Executes immediately at the current market price.
Limit Order: Executes at a specified price or better.
Stop Order: Becomes a market order when a specified price is reached.
Factory Method UML Diagram
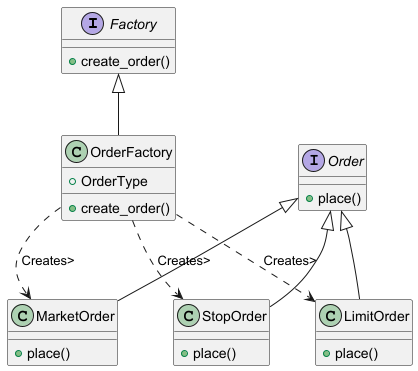
This is the class diagram structure we are implementing.
Product Interface
This interface is common to all the objects (in our case order types) that can be produced by the creator and its subclasses.
trait Order {
fn place(&self);
}
Concrete Products
Concrete Products are different implementations of the product interface. In our case different implementation of order types.
struct MarketOrder {
symbol: String,
quantity: u32,
}
impl Order for MarketOrder {
fn place(&self) {
println!("Placing Market Order: Buy {} units of {} at market price.",
self.quantity, self.symbol
);
// Implement order placement logic here
}
}
struct LimitOrder {
symbol: String,
quantity: u32,
limit_price: f64,
}
impl Order for LimitOrder {
fn place(&self) {
println!("Placing Limit Order: Buy {} units of {} at ${}.",
self.quantity, self.symbol, self.limit_price
);
// Implement order placement logic here
}
}
struct StopOrder {
symbol: String,
quantity: u32,
stop_price: f64,
}
impl Order for StopOrder {
fn place(&self) {
println!(
"Placing Stop Order: Buy {} units of {} when price reaches ${}.",
self.quantity, self.symbol, self.stop_price
);
// Implement order placement logic here
}
}
Creator (Order Factory)
It returns a different type of order.
enum OrderType {
Market,
Limit(f64), // Limit price
Stop(f64), // Stop price
}
struct OrderFactory;
impl OrderFactory {
fn create_order(order_type: OrderType, symbol: String, quantity: u32) -> Box<dyn Order> {
match order_type {
OrderType::Market => Box::new(MarketOrder { symbol, quantity }),
OrderType::Limit(limit_price) => Box::new(LimitOrder {
symbol,
quantity,
limit_price,
}),
OrderType::Stop(stop_price) => Box::new(StopOrder {
symbol,
quantity,
stop_price,
}),
}
}
}
Client Code
fn main() {
let symbol = String::from("AAPL");
let quantity = 100;
// Decide which order type to use
let order_type = OrderType::Limit(149.0);
// Create the order using the factory
let order = OrderFactory::create_order(order_type, symbol.clone(), quantity);
// Place the order
order.place();
}
Singleton Pattern
Singleton is a creational design pattern that lets you ensure that a class has only one instance, while providing a global access point to this instance. Overall Singleton has almost the same pros and cons as global variables and generally a bad idea in context of concurrency.
In Rust, implementing singletons are pretty tricky due to its ownership model and emphasis on safe concurrency. It must solve these two problem:
Ensure a Class Has Only One Instance: Prevents multiple instances, guaranteeing that all clients use the same instance.
Provide a Global Point of Access: Offers a way to access the single instance from anywhere in the application.
Rust discourages global mutable state to prevent data races and ensure thread safety. And any global state must be safe to access from multiple threads. All these makes implementing singletons non-trivial. We can achieve this using different approach like using Mutex, static lifetime, OnceCell crate.
While a mutable singleton can be convenient, global mutable state can lead to code that's difficult to maintain and test. You always have option to pass the instance as a parameter to the parts of your code that needs it. As we are discussing singletons, lets implement using OnceCell.
OnceCell<T>
When you need to initialize data at runtime, possibly in a lazy manner, and ensure it is set only once. The core API looks roughly like
impl OnceCell<T> {
fn new() -> OnceCell<T> { ... }
fn set(&self, value: T) -> Result<(), T> { ... }
fn get(&self) -> Option<&T> { ... }
}
OnceCell has two varient std::cell::OnceCell<T> for single-threaded scenarios and std::sync::OnceCell<T> for thread-safe scenarios, can be shared between threads.
https://github.com/matklad/once_cell
However, since OnceCell provides immutable access to the initialized value, we need a way to mutate the instance after it's been set because singleton patterns allows mutable instance. To achieve a mutable singleton, we need combine OnceCell with interior mutability patterns. This involves wrapping the struct in types that allow mutation through immutable references, such as RefCell for single-threaded applications or Mutex/RwLock for multi-threaded applications.
Example: Trading System ConfigManager
Config
The Config struct holds various configuration settings. It derives Deserialize to allow loading from a JSON file.
use serde::Deserialize;
#[derive(Debug, Deserialize)]
pub struct Config {
pub api_key: String,
pub db_connection_string: String,
pub trading_parameters: TradingParameters,
}
#[derive(Debug, Deserialize)]
pub struct TradingParameters {
pub max_positions: usize,
pub risk_tolerance: f64,
// Add other parameters as needed
}
ConfigManager Singleton
OnceCell ensures that the ConfigManager is initialized only once in a thread-safe manner. instance method provides global access to the singleton instance. The new method is private to prevent direct instantiation.
use once_cell::sync::OnceCell;
use std::fs;
pub struct ConfigManager {
config: Config,
}
impl ConfigManager {
fn new() -> Self {
let config_data = fs::read_to_string("config.json")
.expect("Failed to read configuration file");
let config: Config = serde_json::from_str(&config_data)
.expect("Failed to parse configuration file");
ConfigManager { config }
}
pub fn instance() -> &'static ConfigManager {
static INSTANCE: OnceCell<ConfigManager> = OnceCell::new();
INSTANCE.get_or_init(|| ConfigManager::new())
}
pub fn get_config(&self) -> &Config {
&self.config
}
}
Use ConfigManager
Now we can’t just use this TWAP that depends on a ConfigManager in some other context, without carrying over the ConfigManager to the other context, e.g. Unit Tests.
pub trait OrderExecution {
fn execute(&self);
}
pub struct TWAP;
impl OrderExecution for TWAP {
fn execute(&self) {
let config_manager = ConfigManager::instance();
let max_positions = config_manager.get_config().trading_parameters.max_positions;
let risk_tolerance = config_manager.get_config().trading_parameters.risk_tolerance;
// Implement execution logic using the configurations
}
}
fn main() {
let strategy = TWAP;
strategy.execute();
// Access the ConfigManager directly elsewhere
let api_key = ConfigManager::instance().get_config().api_key.clone();
println!("Using API Key: {}", api_key);
}
In this example, we can't change the ConfigManager instance. We've basically set up an immutable singleton (or a single Flyweight object).
To implement a mutable singleton ConfigManager struct using OnceCell, you need to wrap the ConfigManager in an Interior Mutability Type like using RefCell<ConfigManager> for single-threaded applications or using using Mutex<ConfigManager> or RwLock<ConfigManager> for multi-threaded applications. For example:
static CONFIG: OnceCell<RefCell<ConfigManager>> = OnceCell::new();
//Multi-threaded
static CONFIG: OnceCell<Mutex<ConfigManager>> = OnceCell::new();
Notes on Rust
What is Mutex<T>
Mutex stands for mutual exclusion, which means it is used to protect shared data by allowing only one thread to access a resource or critical section at a time e.g. only exclusive borrows. Once a thread acquires a mutex, all other threads attempting to acquire the same mutex are blocked until the first thread releases the mutex.
The Rust standard library provides std::sync::Mutex<T>. It is generic over a type T, which is the type of the data the mutex is protecting. Its lock() method returns a special type called a MutexGuard. This guard represents the guarantee that we have locked the mutex. You unlock the mutex simply by dropping the guard.
Rust’s Mutex holds the data it’s protecting. In C++, on the other hand, std::mutex doesn’t hold the data it’s protecting and doesn’t even know what it’s protecting.
What is Arc<Mutex<T>>
Here, we want to share ownership of the data (Mutex<T>) between multiple threads. Arc provides shared ownership with thread-safe reference counting. Arc<Mutex<T>> allows multiple threads to own the same data and mutate it safely.
Command Pattern
Command is a behavioral design pattern that turns a request into a stand-alone object that contains all information about the request. This transformation lets you pass requests as a method arguments, delay or queue a request’s execution, and support undoable operations. This definition is by the refactoring.guru. The “Head First Design Pattern” says:
The command pattern encapsulates a request as an object, thereby letting you parameterize other objects with different requests, queue or log requests and support undoable operations.
Let consider an example where we have a Portfolio that keeps track of stock positions and cash balance. We support actions like Add, Remove, or Reduce positions, as well as Deposit and Withdraw funds to our portfolio. Lets make it more interesting and take a step forward and consider multiple treading scenario as one tread could be buying SPY, another selling MSFT and another thread depositing funds. We need to share Portfolio with different threads and it handles different commends.
Structure
Command interface: The Command interface usually methods for executing the command. We can defines
executeandrollbackmethods with thread safety in mind.Receiver: The receiver class contains the business logic. Most commands only handle the details of how a request is passed to the receiver, while the receiver itself does the actual work. In our case the
Portfoliois a receiver that stores positions and balance, protected byMutexfor safe concurrent access.Concrete Commands: Implement the
Commandtrait for specific actions. A concrete command isn’t supposed to perform the work on its own, but rather to pass to the receiver. In our case we will implement add position and add funds commends.Invoker: The Invoker class is responsible for initiating requests. In our example we define a
Brokerthat executes commands and maintains a history.Client: The application that creates commands and interacts with the broker.
Command Trait
use std::error::Error;
trait Command: Send + 'static {
fn execute(&mut self) -> Result<(), Box<dyn Error>>;
fn rollback(&mut self) -> Result<(), Box<dyn Error>>;
}
Send Trait ensures commands can be transferred across threads. The Box<dyn Error> is for flexible error types.
Receiver: Portfolio
use std::collections::HashMap;
use std::sync::{Arc, Mutex};
#[derive(Clone)]
struct Portfolio {
positions: Arc<Mutex<HashMap<String, i32>>>, // symbol -> quantity
balance: Arc<Mutex<f64>>, // cash balance
}
impl Portfolio {
fn new() -> Self {
Portfolio {
positions: Arc::new(Mutex::new(HashMap::new())),
balance: Arc::new(Mutex::new(0.0)),
}
}
fn add_position(&self, symbol: &str, quantity: i32) -> Result<(), String> {
let mut positions = self.positions.lock().unwrap();
let entry = positions.entry(symbol.to_string()).or_insert(0);
*entry += quantity;
println!("Added {} shares of {}", quantity, symbol);
Ok(())
}
fn reduce_position(...){...} //Similar
fn deposit(&self, amount: f64) -> Result<(), String> {
let mut balance = self.balance.lock().unwrap();
*balance += amount;
println!("Deposited ${}", amount);
Ok(())
}
fn withdraw(...){...} //Similar to deposit
fn get_balance(&self) -> f64 {
let balance = self.balance.lock().unwrap();
*balance
}
fn get_positions(&self) -> HashMap<String, i32> {
let positions = self.positions.lock().unwrap();
positions.clone()
}
}
We used Arc<Mutex<HashMap<String, i32>>> to allow shared mutable access across threads for position.
Concrete Commands
We implement two concreate commands AddPositionCommand and WithdrawCommand. Both command interacts with the Portfolio in a thread-safe manner and implements rollback functionality.
struct AddPositionCommand {
receiver: Arc<Portfolio>,
symbol: String,
quantity: i32,
}
impl Command for AddPositionCommand {
fn execute(&mut self) -> Result<(), Box<dyn Error>> {
self.receiver.add_position(&self.symbol, self.quantity)?;
Ok(())
}
fn rollback(&mut self) -> Result<(), Box<dyn Error>> {
self.receiver.reduce_position(&self.symbol, self.quantity)?;
Ok(())
}
}
struct WithdrawCommand {
receiver: Arc<Portfolio>,
amount: f64,
}
impl Command for WithdrawCommand {
fn execute(&mut self) -> Result<(), Box<dyn Error>> {
self.receiver.withdraw(self.amount)?;
Ok(())
}
fn rollback(&mut self) -> Result<(), Box<dyn Error>> {
self.receiver.deposit(self.amount)?;
Ok(())
}
}
Invoker: Broker
struct Broker {
history: Vec<Box<dyn Command>>,
}
impl Broker {
fn new() -> Self {
Broker {
history: Vec::new(),
}
}
fn execute_command(&mut self, mut command: Box<dyn Command>) -> Result<(), Box<dyn Error>> {
command.execute()?;
self.history.push(command);
Ok(())
}
fn rollback_last(&mut self) -> Result<(), Box<dyn Error>> {
if let Some(mut command) = self.history.pop() {
command.rollback()?;
Ok(())
} else {
Err("No commands to rollback.".into())
}
}
}
Client Code
fn main() -> Result<(), Box<dyn std::error::Error>> {
let portfolio = Arc::new(Portfolio::new());
let broker = Arc::new(Mutex::new(Broker::new()));
let portfolio_clone1 = Arc::clone(&portfolio);
let broker_clone1 = Arc::clone(&broker);
// Add position
let add_position_command = AddPositionCommand {
receiver: portfolio.clone(),
symbol: "AAPL".to_string(),
quantity: 50,
};
let deposit_handle = thread::spawn(move || {
let deposit_command = DepositCommand {
receiver: portfolio_clone1,
amount: 10000.0,
};
let mut broker1 = broker_clone1.lock().unwrap();
broker1.execute_command(Box::new(deposit_command)).unwrap();
drop(broker1);
});
let broker_clone2 = Arc::clone(&broker);
{
let mut broker2 = broker_clone2.lock().unwrap();
broker2.execute_command(Box::new(add_position_command))?;
}
deposit_handle.join().unwrap();
// Print current portfolio state
println!("Current balance: ${}", portfolio.get_balance());
println!("Current positions: {:?}", portfolio.get_positions());
// Rollback last command (Withdraw)
{
let mut broker3 = broker.lock().unwrap();
broker3.rollback_last()?;
}
println!("\nAfter rollback of last command:");
println!("Current balance: ${}", portfolio.get_balance());
println!("Current positions: {:?}", portfolio.get_positions());
Ok(())
}

Here, I used Arc<Mutex<Broker>> to let multiple threads share access to the broker, ensuring the execute_command method is synchronized. While this isn't the perfect example since locking Broker might slow things down, it gives you a taste of multithreading and the command pattern.
As Broker might be doing tons of other operation we should at least minimize locking and lock only history to prevent contention and improve performance.
So, let's take out the Mutex around the Broker and redesign the broker as:
struct Broker {
history: Arc<Mutex<Vec<Box<dyn Command>>>>,
}
Now, the history is an Arc<Mutex<Vec<Box<dyn Command>>>>, which lets multiple parts of the program access the Broker at the same time while keeping the history synchronized.
The ring buffer pattern
The ring buffer pattern is not listed as a design pattern in the GoF book. It is more of a data structure or Producer-Consumer pattern than a design pattern. However, it is relevant in trading systems and fundamental for other pattern to understand. Let's dive in. Challenges Ahead!
The ring buffer as name suggest offers a fixed-size buffer that replaces old data when it fills up, making it perfect for processing data streams without interruption. It operates as a circular queue data structure, maintaining a first-in, first-out (FIFO) behavior, guided by two indices: one for reading and another for writing. So far so good.
🔗What Is a Ring Buffer?
A ring buffer is a fixed-size data structure that uses a single, contiguous block of memory in a circular fashion. When the write pointer reaches the end of the buffer, it wraps around to the beginning, overwriting the oldest data. Since it's a fixed-size buffer, it doesn't require dynamic memory allocation, and reading/writing operations are generally constant time, O(1), making it highly desirable for low latency.
It has two pointers:
Head (Write Pointer): Indicates where the next data element will be written.
Tail (Read Pointer): Indicates where the next data element will be read.
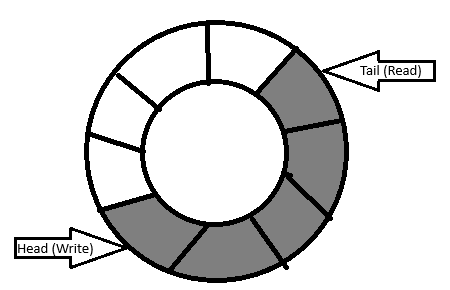
Define the Ring Buffer Struct
We have learned the multithreading and Mutex in previous section. We can assume there will be two thread one for consumer and one for producer. As in the previous section we can use Mutex to lock head and tail and we should be good. However in this example we will do Lock-Free Ring Buffer Implementation for a Single Producer and Single Consumer. In general you almost never need to do the lock-free implementation (warning: stay away from Atomic), and your life is much better to just use locks. But we will do anyway, otherwise, how would we learn the Atomic and memory ordering. This is going to be mind blowing.
Lets define the RingBuffer struct.
pub struct RingBuffer<T> {
buffer: Vec<UnsafeCell<MaybeUninit<T>>>,
capacity: usize,
head: AtomicUsize, // Index for the producer
tail: AtomicUsize, // Index for the consumer
}
In this example, we're diving into the unsafe part, which means we're turning off some of the compiler's safety features. First, let's revisit some Rust concepts together.
What is Cell<T>?
Cell<T> is a type in Rust's standard library that provides interior mutability for values that implement the Copy trait. It allows you to get and set the value inside the Cell<T> even when you have only an immutable reference to it. This is particularly useful when you need to mutate data within a struct that is otherwise immutable.
There are scenarios where you need to mutate data even though you have only an immutable reference to it. This pattern is known as interior mutability. Cell<T> enables interior mutability by encapsulating the value and providing methods to access and modify it without requiring a mutable reference to the Cell<T> itself. Internally, it uses UnsafeCell<T> to bypass Rust's usual borrowing rules safely.
use std::cell::Cell;
fn main() {
let cell = Cell::new(10);
// Even though `cell` is immutable, we can get and set its value.
println!("Initial value: {}", cell.get());
cell.set(20);
println!("Updated value: {}", cell.get());
}

What is UnsafeCell<T>?
UnsafeCell<T> is a type that wraps some T and indicates unsafe interior operations on the wrapped type. Types like Cell<T> and RefCell<T> in Rust's standard library are built upon UnsafeCell<T>. The UnsafeCell API .get() gives you a raw pointer *mut T to its contents. It is up to you to use that raw pointer correctly.
Let's create our own cell!
use std::cell::UnsafeCell;
struct MyCell<T> {
value: UnsafeCell<T>,
}
impl<T> MyCell<T> {
fn new(value: T) -> MyCell<T> {
MyCell {
value: UnsafeCell::new(value),
}
}
fn get(&self) -> &T {
unsafe { &*self.value.get() }
}
fn set(&self, new_value: T) {
unsafe {
*self.value.get() = new_value;
}
}
}
fn main() {
let cell = MyCell::new(42);
println!("Cell value: {}", cell.get());
cell.set(24);
println!("Cell value: {}", cell.get());
}

You have immutable cell with value 42 and and you can set to 24 without any problem.
Before we move to implementation, lets visit one more concepts Send and Sync.
impl<T: Send> Sync for StructName {}
In Rust, the Send and Sync traits are fundamental to the language's concurrency guarantees. They determine how types can be safely shared or transferred across threads when you see a line like
impl<T: Send> Sync for StructName<T> {}
It means that we're implementing the Sync trait for the type StructName<T>, where T is any type that implements Send. This implementation allows references to StructName<T> to be shared safely across multiple threads, provided that T is Send. A type T is Send if it is safe to transfer ownership of values of type T to another thread. A type T is Sync if it is safe to share references (&T) to T between multiple threads.
Here we are asserting to the compiler that StructName<T> is Sync whenever T is Send and allow us to share the references to StructName<T> safely shared between threads.
struct StructName<T> {
data: T,
}
impl<T: Send> Sync for StructName<T> {}
When we compile this code, we see the error that says “An unsafe trait was implemented without an unsafe implementation.”
error[E0200]: the trait Sync requires an unsafe impl declaration
|
27 | impl<T: Send> Sync for StructName<T> {}
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: the trait `Sync` enforces invariants that the compiler can't check.
Review the trait documentation and make sure this implementation upholds those invariants before adding the `unsafe` keyword
help: add `unsafe` to this trait implementation
|
27 | unsafe impl<T: Send> Sync for StructName<T> {}
| ++++++
As compiler cannot check its safety, we need to add ‘unsafe’ keyword. The unsafe keyword indicates that you are taking responsibility for ensuring that your implementation upholds the required safety guarantees.
What is MaybeUninit<T>?
A type that represents uninitialized memory. MaybeUninit<T> serves to enable unsafe code to deal with uninitialized data. It is a signal to the compiler indicating that the data here might not be initialized. Refer to below link for more details and examples.
https://doc.rust-lang.org/std/mem/union.MaybeUninit.html
Overall UnsafeCell and MaybeUninit provide safer abstractions over raw pointers.
assume_init_read(&self) -> T and assume_init_ref(&self) -> T
assume_init_read reads the value from the MaybeUninit<T> container. The resulting T is subject to the usual drop handling. This function creates a bitwise copy of the contents, regardless whether the contained type implements the Copy trait or not.
assume_init_ref gets a shared reference to the contained value. This can be useful when we want to access a MaybeUninit that has been initialized but don’t have ownership of the MaybeUninit (preventing the use of .assume_init()).
Ring Buffer Implementation
unsafe impl<T: Send> Sync for RingBuffer<T> {}
impl<T> RingBuffer<T> {
pub fn new(capacity: usize) -> Self {
let mut buffer = Vec::with_capacity(capacity);
for _ in 0..capacity {
buffer.push(UnsafeCell::new(MaybeUninit::uninit()));
}
RingBuffer {
buffer,
capacity,
head: AtomicUsize::new(0),
tail: AtomicUsize::new(0),
}
}
pub fn push(&self, item: T) -> Result<(), T> {
let head = self.head.load(Ordering::Acquire);
let next_head = (head + 1) % self.capacity;
// Check if buffer is full
if next_head == self.tail.load(Ordering::Acquire) {
// Buffer is full
return Err(item);
}
unsafe {
let cell = self.buffer[head].get();
(*cell).write(item);
}
self.head.store(next_head, Ordering::Release);
Ok(())
}
pub fn pop(&self) -> Option<T> {
let tail = self.tail.load(Ordering::Relaxed);
if tail == self.head.load(Ordering::Acquire) {
// Buffer is empty
return None;
}
let item = unsafe {
let cell = self.buffer[tail].get();
(*cell).assume_init_read()
};
let next_tail = (tail + 1) % self.capacity;
self.tail.store(next_tail, Ordering::Release);
Some(item)
}
}
impl<T> Drop for RingBuffer<T> {
fn drop(&mut self) {
// Clean up any initialized elements
let head = self.head.load(Ordering::Relaxed);
let tail = self.tail.load(Ordering::Relaxed);
let mut idx = tail;
while idx != head {
unsafe {
let cell = self.buffer[idx].get();
(*cell).assume_init_drop();
}
idx = (idx + 1) % self.capacity;
}
}
}
Let's go through this step by step. There's a lot to understand. We've already talked about MaybeUninit<T> and its methods, which are quite low-level. But what do Ordering::Acquire or Ordering::Release mean when we read and update head and tail? Memory ordering is the next concept we need to discuss.
Memory Ordering
In simple terms, memory ordering refers to the sequence in which read and write operations on memory happen in a concurrent or multi-threaded environment. This order can vary because of optimizations like instruction reordering, caching, and the architecture's memory model.
Compilers and CPUs re-order your instructions to optimize the performance. We use AtomicUsize and its method e.g. store, load, swap, compare_and_swap, etc. These atomic operation is an indivisible operation that appears instantaneous to other threads. It ensures that no other thread can observe the operation in a partially completed state. When using atomic operations, we need to specify the memory ordering, which controls how operations are ordered with respect to other memory operations.
Common C++ Memory Orderings are:
Relaxed (
memory_order_relaxed): No ordering constraints; only atomicity is guaranteed.Acquire (
memory_order_acquire): Prevents memory reordering of subsequent reads/writes.Release (
memory_order_release): Prevents memory reordering of previous reads/writes.Acquire-Release: Combines acquire and release semantics.
Sequentially Consistent (
memory_order_seq_cst): Provides a total ordering; all threads agree on the order of operations.
Different CPU architectures have different memory models:
x86/x64 (Intel/AMD): Generally strong memory ordering; most reads and writes are not reordered.
ARM, PowerPC: Allow more reordering; require explicit memory barriers to enforce ordering.
Memory Ordering in Rust
Rust uses the same memory model as C++ for atomic operations. Memory Ordering is specified using Ordering enum. Ordering Variants in Rust
Ordering::RelaxedOrdering::AcquireOrdering::ReleaseOrdering::AcqRelOrdering::SeqCst
This is a complicated topic, so for now, we'll just follow a few simple rules. We'll skip Ordering::Relaxed because it is quite weak. We can discuss it further later.
We apply Ordering::Release when writing to an atomic variable that will be read by other threads. It guarantees that all memory writes (before the release store) in the current thread become visible to other threads that perform an acquire load on the same atomic variable. In a way it says "I'm releasing my changes so other threads can see them."
We apply Ordering::Acquire when reading from an atomic variable that was written by other threads. It guarantees that all memory reads and writes (after the acquire load) in the current thread see the effects of the writes that happened before the release store in another thread. In a way it says "I'm acquiring the latest changes made by other threads."
Together, they ensure that memory operations are properly ordered and visible across threads, enabling safe and correct concurrent programming.
#[derive(Debug,Clone)]
pub struct MarketDataTick {
pub symbol: String,
pub price: f64,
pub volume: u32,
pub timestamp: u32,
}
fn start_producer(buffer: Arc<RingBuffer<MarketDataTick>>) {
thread::spawn(move || {
let symbols = vec!["AAPL", "GOOG", "MSFT", "AMZN"];
let mut tick_count:u32 = 0;
loop {
let symbol = symbols[tick_count as usize % symbols.len()].to_string();
let tick = MarketDataTick {
symbol,
price: 100.0 + tick_count as f64,
volume: 1000 + tick_count,
timestamp: tick_count,
};
while buffer.push(tick.clone()).is_err() {
// Buffer is full, handle accordingly
println!("Buffer full, retrying...");
thread::sleep(Duration::from_millis(1));
}
println!("Produced tick {}", tick_count);
tick_count += 1;
// Simulate data arrival rate
thread::sleep(Duration::from_millis(10));
}
});
}
fn start_consumer(buffer: Arc<RingBuffer<MarketDataTick>>) {
thread::spawn(move || {
loop {
match buffer.pop() {
Some(tick) => {
println!("Consumed tick: {:?}", tick);
// Simulate processing time
thread::sleep(Duration::from_millis(15));
}
None => {
// Buffer is empty, wait for new data
thread::sleep(Duration::from_millis(1));
}
}
}
});
}
fn main() {
let buffer_capacity = 100;
let ring_buffer = Arc::new(RingBuffer::new(buffer_capacity));
// Start producer and consumer threads
start_producer(ring_buffer.clone());
start_consumer(ring_buffer.clone());
// Let the simulation run for a while
thread::sleep(Duration::from_secs(5));
}
State Pattern
State is a behavioral design pattern that lets an object changes its behavior when its internal state changes. It's a pretty popular pattern from the Gang of Four 23 popular design patterns. I first learned this pattern from Head-First Design Pattern, so lets see what it says:
The state pattern allows an object to alter its behavior when its internal state changes. The object will appear to change its class.
Imagine you have a trading system, and its behavior depends on its current state. Risk management is an essential part of any trading system, and you have integrated it into your system to enforce the right controls to adjust the system behavior based on current level of risk.
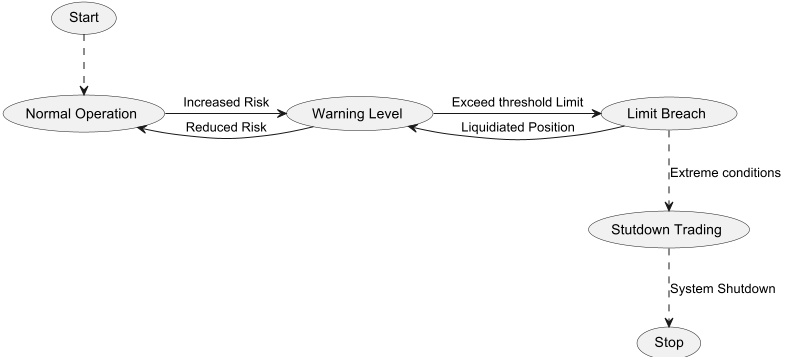
The state pattern can represent different risk states. Let’s consider an example where we have a "normal operation" state, where trading activities proceed as usual. If you take on a significant amount of risk and the VaR (Value at Risk) of your current position approaches the VaR limit (we'll discuss VaR later, but for now, remember that VaR measures risk in dollar terms), you enter a different state, let's call it the "Warning Level" state. This state limits your trading, increases monitoring, and sends email notifications about any additional positions. If you continue and exceed the VaR by a certain amount, it triggers another state, called the "Limit Breach" state. This state blocks new trades, may close existing positions, and allows for hedging. If you cannot close positions for some time and the situation worsens, it enters the "Shutdown Trading" state and starts shutdown procedures.
The benefits of using state pattern is that your system adapts to changing risk levels in real-time and changes its behavior. Risk policies, actions and controls are encapsulated within each state. The concepts and UML diagram of state pattern is similar to the strategy pattern.
Key Concepts of the State Pattern
Context: The object that changes how it behaves based on its internal state. Context keeps a reference to one of the specific state objects and lets it handle all the work related to that state.
State: An interface that defines the behavior associated with a particular state of the Context. The State interface declares the state-specific methods.
Concrete States: Implementations of the State interface that define the behavior for each state.
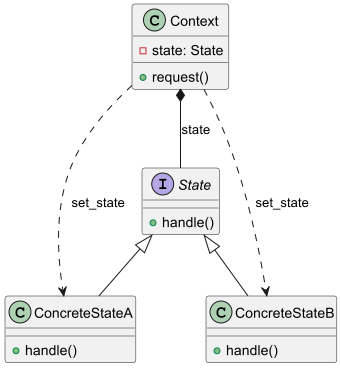
Example: Risk Management system
We'll model a risk management system that transitions through various states based on the Value at Risk (VaR) of the current trading positions. The states we'll implement are:
NormalOperationState: Trading proceeds as usual.
WarningLevelState: Trading is limited, monitoring is increased, and notifications are sent.
LimitBreachState: New trades are blocked, existing positions may be closed, and hedging is allowed.
ShutdownState: Trading is halted, and shutdown procedures are initiated.
Define a State: RiskState trait
We'll define a RiskState trait that declares the methods each state must implement.
pub trait RiskState: fmt::Debug {
fn check_var(&self, context: &RiskManager) -> Option<Box<dyn RiskState>>;
fn enter_state(&self, context: &RiskManager);
fn exit_state(&self, context: &RiskManager);
fn send_command(&self, context: &RiskManager);
}
check_var method will be called to check the current VaR and decide if a state transition is needed. enter_state and exit_state methods can perform actions when entering or exiting a state (e.g., sending notifications, adjusting trading limits). send_command will be used to send commend to trading engine based on the state.
Define the Context": RiskManager
pub struct RiskManager {
state: Box<dyn RiskState>,
pub var_limit: f64,
pub warning_level: f64,
pub current_var: f64,
pub positions: HashMap<String, f64>, // Position ID -> VaR contribution
trading_engine_sender: Sender<TradingEngineCommand>,
}
The RiskManager struct will hold the current state, VaR limits, current VaR, and methods to update VaR and handle state transitions.
pub enum TradingEngineCommand {
ExecuteTrade,
NoTrade,
StopEngine,
}
TradingEngineCommand is the enum that we send as command to TradingEngine thread using mpsc channel.
pub struct TradingEngine;
impl TradingEngine {
pub fn start(receiver: mpsc::Receiver<TradingEngineCommand>) {
thread::spawn(move || {
println!("Trading engine started.");
loop{
let cmd = receiver.recv().unwrap();
match cmd {
TradingEngineCommand::ExecuteTrade => {
println!("Executing trade");
}
TradingEngineCommand::StopEngine => {
println!("Stopping trading engine.");
// Perform cleanup if necessary
break;}
TradingEngineCommand::NoTrade => {
println!("No trade to execute.");}
}
}
println!("Trading engine stopped.");
});
}}
Let's implement the RiskManager. You can think of the RiskManager as being between the trading signals and the actual trading engine. The RiskManager receives the trade, checks its risk and state, and then sends a command to the trading engine to either trade, hold, or stop. Let's go through this step by step.
update_var: Recalculates the current VaR based on positions.add_positionandremove_position: Modify positions and update VaR.check_state: Checks if a state transition is needed based on the current VaR.change_state: Handles the transition between states, callingexit_stateon the old state andenter_stateon the new state.send_command: Based on the state, it sends the command to the trading engine thread.
impl RiskManager {
pub fn new(var_limit: f64, warning_level: f64, trading_engine_sender: Sender<TradingEngineCommand>) -> Self {
let mut manager = RiskManager {
state: Box::new(NormalOperationState{cmd: TradingEngineCommand::ExecuteTrade}),
var_limit,
warning_level,
current_var: 0.0,
positions: HashMap::new(),
trading_engine_sender,
};
manager
}
pub fn update_var(&mut self) {
self.current_var = self.positions.values().sum();
}
pub fn add_position(&mut self, position_id: &str, var_contribution: f64) {
self.positions.insert(position_id.to_string(), var_contribution);
self.update_var();
self.check_state();
self.send_command();
}
pub fn remove_position(&mut self, position_id: &str) {
self.positions.remove(position_id);
self.update_var();
self.check_state();
self.send_command();
}
pub fn send_command(&self) {
self.state.send_command(&self);
}
pub fn check_state(&mut self) {
match self.state.check_var(self){
Some(state) => self.change_state(state),
None => (),
}
}
pub fn change_state(&mut self, new_state: Box<dyn RiskState>) {
self.state.exit_state(self);
self.state = new_state;
self.state.enter_state(self);
}
pub fn should_shutdown(&self) -> bool {
self.current_var >= self.var_limit * 1.2
}
}
Implement Concrete States: NormalOperationState
#[derive(Debug)]
struct NormalOperationState{
cmd: TradingEngineCommand
}
impl RiskState for NormalOperationState {
fn check_var(&self, context: &RiskManager) -> Option<Box<dyn RiskState>> {
if context.current_var >= context.warning_level && context.current_var < context.var_limit {
Some(Box::new(WarningLevelState{cmd: TradingEngineCommand::ExecuteTrade}))
} else if context.current_var >= context.var_limit {
Some(Box::new(LimitBreachState{cmd: TradingEngineCommand::NoTrade}))
} else {
None
}
}
fn enter_state(&self, _context: &RiskManager) {
println!("Entering Normal Operation State");
// Reset limitations
}
fn exit_state(&self, _context: &RiskManager) {
println!("Exiting Normal Operation State");
}
fn send_command(&self, context: &RiskManager) {
context.trading_engine_sender.send(self.cmd.clone());
}
}
fn send_email_notification(message: &str) {
println!("Sending email notification: {}", message);
}
The WarningLevelState, LimitBreachState, and ShutdownState work pretty much the same way, so we don't need to spell them out here.
Client
Let's write a main function that simulates adding positions and triggering state transitions.
fn main() {
let var_limit = 100.0;
let warning_level = 80.0;
let (trading_engine_sender, trading_engine_receiver) = mpsc::channel();
TradingEngine::start(trading_engine_receiver);
let mut risk_manager = RiskManager::new(var_limit, warning_level, trading_engine_sender);
risk_manager.add_position("Position1", 30.0);
println!("Current VaR: {}", risk_manager.current_var);
risk_manager.add_position("Position2", 40.0);
println!("Current VaR: {}", risk_manager.current_var);
risk_manager.add_position("Position3", 20.0);
println!("Current VaR: {}", risk_manager.current_var);
risk_manager.add_position("Position4", 15.0);
println!("Current VaR: {}", risk_manager.current_var);
risk_manager.add_position("Position5", 35.0);
println!("Current VaR: {}", risk_manager.current_var);
// Simulate the passage of time and check if shutdown is needed
risk_manager.check_state();
std::thread::sleep(std::time::Duration::from_secs(2));
}
The RiskManager begins in the NormalOperationState. As you add positions and the current_var goes over the warning_level, it moves to the WarningLevelState. If the current_var goes beyond the var_limit, it shifts to the LimitBreachState. And if it surpasses 120% of the var_limit, it enters the ShutdownState. You can check out the full implementation here: https://github.com/siddharthqs/design-patterns-in-rust
The RiskManager interacts with the trading engine appropriately based on its current state, ensuring that state-specific jobs are performed correctly.
Template Method Pattern
The Template Method Pattern is a behavioral design pattern that defines the skeleton of an algorithm in a method, deferring some steps to subclasses without changing the overall algorithm's structure. This pattern lets subclasses redefine certain steps of an algorithm without altering its structure.
This pattern is all about creating a template for an algorithm and allow subclasses to provide concreate implementation for some of the steps. It's like a blueprint for an algorithm that can be customized by subclasses. You can place your own custom logic in the template method and override the steps that need to be customized.
Key Concepts
Abstract Class or Trait: Defines the template method and declares abstract methods representing steps that can vary.
Template Method: A method that defines the skeleton of an algorithm, calling abstract methods that subclasses will implement.
Concrete Subclasses : Provide implementations for the abstract methods, customizing the behavior of the algorithm.

In Rust, the Template Method Pattern can be implemented using traits with default method implementations. This lets concrete types override specific behaviors. It's one of the most commonly used patterns!
In nearly every financial application, we use a Monte Carlo simulation framework, whether it's for pricing derivatives, managing risk, or generating simulations for backtesting. In this chapter, we'll implement the Monte Carlo Simulation using the template method pattern.
Example: Monte Carlo Simulation
In a nutshell, the concept of Monte Carlo simulation is pretty straightforward; it involves generating random numbers and averaging of the outcome.
We'll define a trait MCSimulation that provides default implementations for generating random numbers and a template method simulation(). The simulation() method first calls generate_random_numbers() and then calls generate_path(). The generate_path() function does not have an implementation in the trait and must be provided by concrete structs like GeometricBrownianMotion.
By using the Template Method Pattern, we can define the skeleton of the simulation algorithm while allowing subclasses to customize specific steps.
Defining the MCSimulation Trait
Let’s define the MCSimulation trait that includes a default implementation for generating standard normal random numbers, a template method simulation() and an abstract method that must be implemented by the structs that implement the trait.
pub trait MCSimulation {
/// Generates a vector of standard normal random numbers.
fn generate_random_numbers(&self, num: usize) -> Vec<f64> {
let mut rng = rand::thread_rng();
(0..num).map(|_| rng.sample(StandardNormal)).collect()
}
/// Template method that runs the simulation.
fn simulation(&self) -> Vec<f64> {
let random_numbers = self.generate_random_numbers(self.get_number_of_steps());
self.generate_path(&random_numbers)
}
/// Abstract method to generate the path based on random numbers.
fn generate_path(&self, random_numbers: &[f64]) -> Vec<f64>;
fn get_number_of_steps(&self) -> usize;
}
simulation() is the template method that use generate_path(), an abstract method to be implemented by concrete structs, defining how to generate the simulation path.
Implement StochasticProcess Trait
We define StochasticProcess trait for the underlying asset's stochastic process.
pub trait StochasticProcess {
fn drift(&self, dt: f64) -> f64;
fn diffusion(&self, dt: f64) -> f64;
}
Geometric Brownian Motion
GeometricBrownianMotionimplements StochasticProcess
pub struct GeometricBrownianMotion {
pub initial_value: f64,
pub risk_free_rate: f64,
pub volatility: f64,
pub time_steps: usize,
pub maturity: f64,
}
impl StochasticProcess for GeometricBrownianMotion {
fn drift(&self, _dt: f64) -> f64 {
(self.risk_free_rate - 0.5 * self.volatility.powi(2))* _dt
}
fn diffusion(&self, _dt: f64) -> f64 {
self.volatility * _dt.sqrt()
}
}
Implementing MCSimulation
Now, let's have GeometricBrownianMotion implement the MCSimulation trait. It defines how to generate a path based on the Geometric Brownian Motion model.
impl MCSimulation for GeometricBrownianMotion {
fn get_number_of_steps(&self) -> usize {
self.time_steps
}
fn generate_path(&self, random_numbers: &[f64]) -> Vec<f64> {
let dt = self.maturity / self.time_steps as f64;
let mut s = self.initial_value;
let mut path = Vec::with_capacity(self.time_steps + 1);
path.push(s);
for &dw in random_numbers {
let drift = self.drift(dt);
let diffusion = self.diffusion(dt) * dw ;
s = s * (drift + diffusion).exp();
path.push(s);
}
path
}
}
Using the Simulation in Client Code
fn main() {
let gbm = GeometricBrownianMotion {
initial_value: 100.0,
risk_free_rate: 0.05,
volatility: 0.2,
time_steps: 1000,
maturity: 1.0,
};
let path = gbm.simulation();
println!("Generated GBM path: {:?}", path);
}
We call the simulation() method, which generates a path using the Template Method Pattern.
By using the Template Method Pattern, we've created a flexible and extensible Monte Carlo simulation framework in Rust. The MCSimulation trait defines the overall simulation process, while concrete structs like GeometricBrownianMotion provide specific implementations for generating simulation paths. You can extend this framework to include other stochastic processes, such as the Heston model or the Cox-Ingersoll-Ross model, by implementing the generate_path() method accordingly.
Limit-Order Book (LOB)
Todo!
Conclusion
Design patterns like Strategy, Decorator, Observer, and Factory Method provide proven and adaptable solutions that help developers create strong and efficient trading systems. By learning and using these patterns, developers can greatly improve the quality, maintainability, and performance of algorithmic trading systems. By abstracting the creation of objects, by encapsulating execution and trading strategies separately, we can build systems that are easier to maintain, extend, and adapt to changing market conditions.
References
https://refactoring.guru/design-patterns/strategy
https://rust-unofficial.github.io/patterns/patterns/index.html




